Updates
Abstract
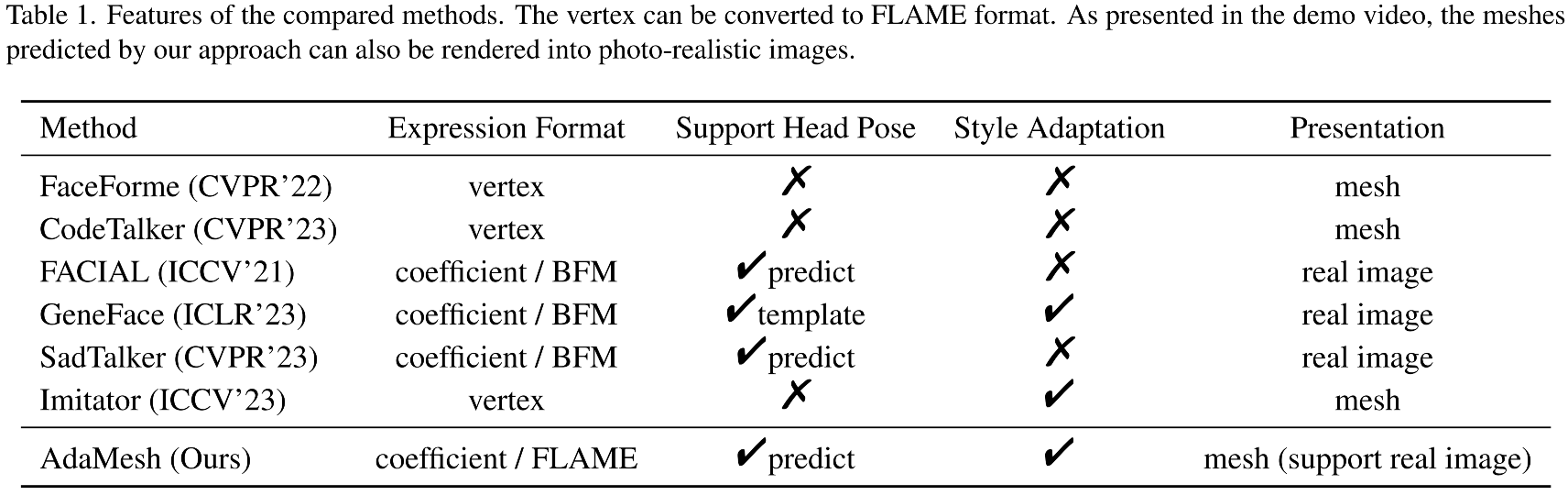
Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation.

Approach
Expression Adapter
To achieve efficient adaptation for facial expressions, we pre-train the expression adapter to learn general and person-agnostic information that ensures lip synchronization and then optimize the MoLoRA parameters to equip the expression adapter with a specific expression style.
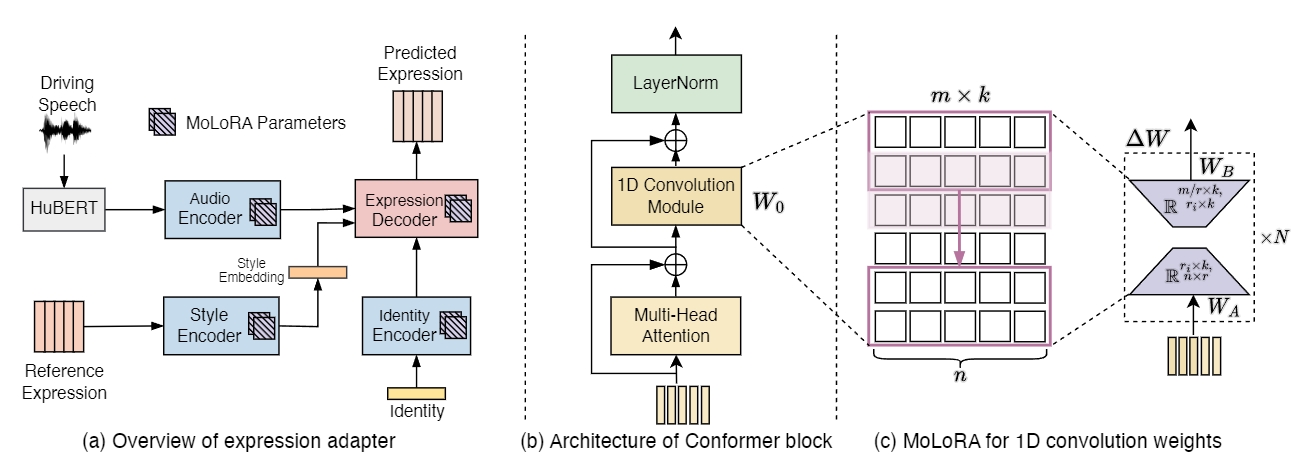
Pose Adapter
For modeling the pose style, we propose a pose adapter by formulating the adaption as a simple but efficient retrieval task instead of fine-tuning modules.
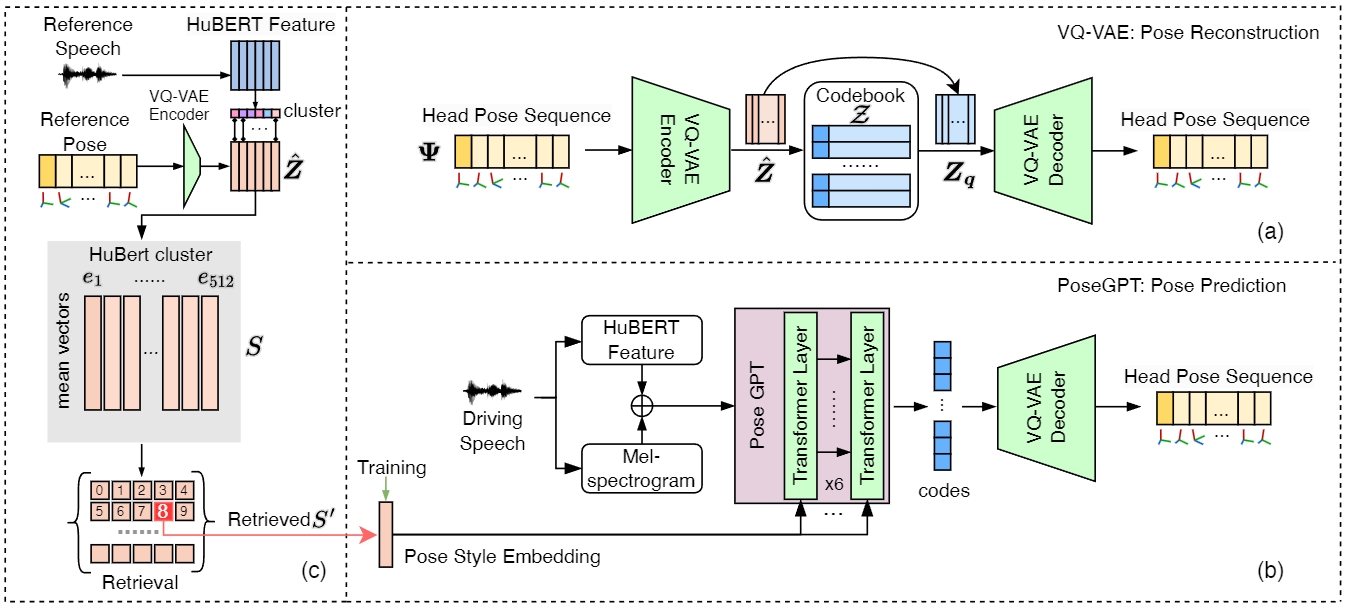
Features of Compared Methods